Question
How do I identify overcollisioned token issues?
Answer
Nosy words
-
To identify the cause of overcollisioned tokens generation we have to have examples of the token and entities that produce it. For analysis, we will use the Get match tokens detailed endpoint. In the result of the endpoint, we will see JSON with information on how the token was built.
- For example, we have overcollisioned token
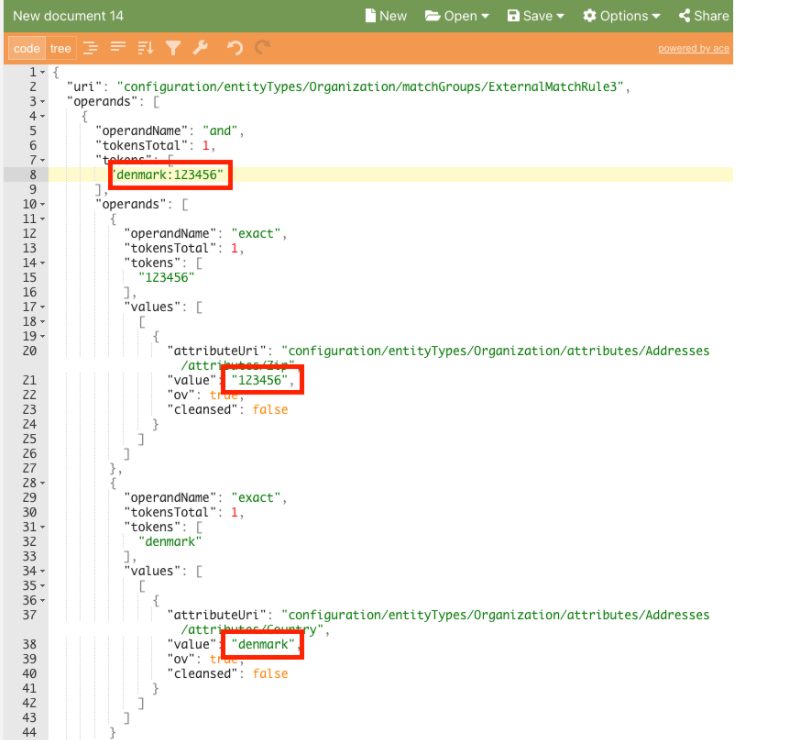
denmark:a-sand entity ID. As we can see token has 2 attributes values separated by “:“. In the response of the token generation endpoint, we see the first part is coming from the exact attribute “City” and the second part is coming from the fuzzy attribute “Organisation/Name“

- From this information, we can say that token generation creates token "a-s" from the organization name which looks like a nosy word. It means that to resolve the issue with the rule we have to use an organization names cleanser to remove nosy words before the tokenization process started.
Low cardinality attributes
The issue accrues when a rule has only low cardinality attributes.
-
To identify the cause of overcollisioned tokens generation we have to have examples of the token and entities that produce it. For analysis, we will use Get match tokens detailed endpoint. In the result of the endpoint, we will see JSON with information on how the token was built.
-
For example, we have overcollisioned token
denmark:123456and entity ID. As we can see token has 2 attributes values separated by “:“. In the response of the token generation endpoint, we see the first part is coming from the exact attribute “City” and the second part is coming from the exact attribute “Zip“.
How to identify issues with the generation of big amount of tokens
-
To identify the cause of the issue we have to have examples of entities that produce tokens more than the limit. For analysis, we will use Get match tokens detailed endpoint. In the result of the endpoint, we will see JSON with information on how the tokens were built.

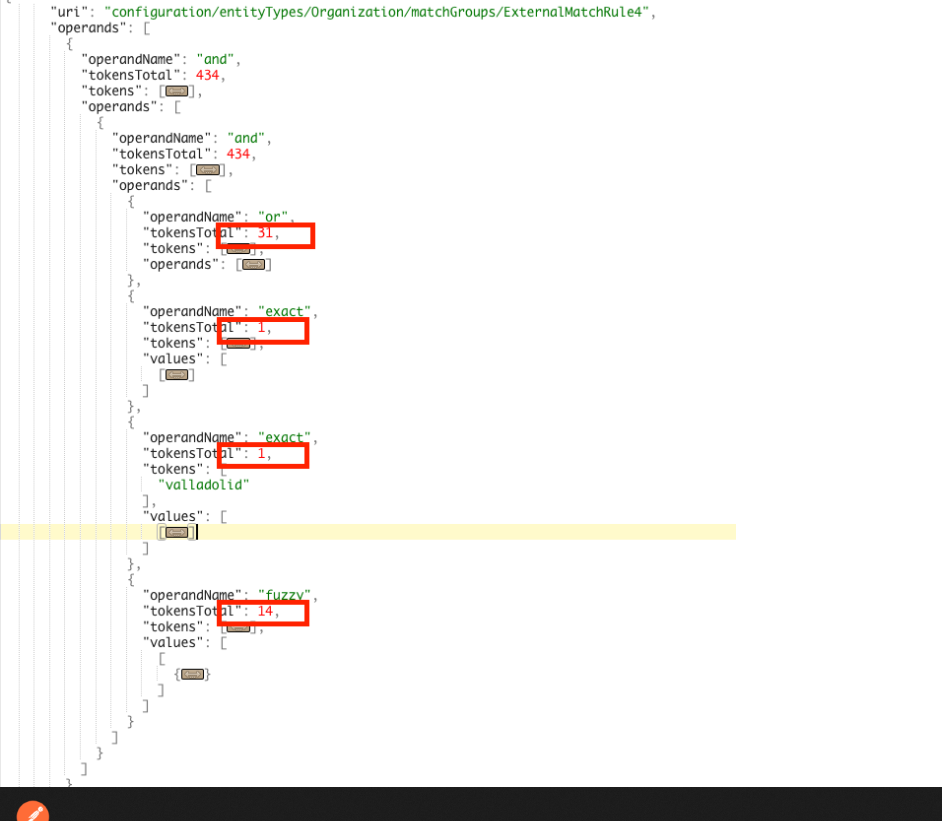
- We will start from 14 tokens part attribute. As we can see the token part generates by the attribute City. In the business configuration, we can see that the token has the configuration:
- For example, we have an entity with the rule where the number of tokens is more than the limit(by default 300)
- In the response, we can see that rule contains several parts which participated in a token generation. We can see that token generates with 31*1*1*14=434 tokens we will have in total. We need to review why the first and second part generates 31 and 14 token parts.

Comments
Please sign in to leave a comment.